
Docker for Academia: Streamlining Research and Development
A Guide to Implementing Containers for Machine Learning, HPC, and Research Software


Table of contents
Introduction
Docker is a platform that enables developers to easily create, deploy, and run applications in containers. This technology has become increasingly popular in recent years and has proven to be a valuable tool for researchers and developers alike. The main advantage of using Docker in academia is that it allows for easier collaboration and reproducibility of results. In this blog, we will explore the implementation of Docker in academia, including its benefits and use cases, as well as some code examples.
Benefits
Benefits of using Docker in Academia:
Portability: Docker containers can be easily moved from one environment to another, making it easy to collaborate with other researchers or share results with others.
Reproducibility: Docker containers can be used to ensure that the same environment and dependencies are used for every run of an experiment, making it easier to reproduce results.
Scalability: Docker can be used to deploy applications on a large scale, making it easy to run experiments on large datasets.
Isolation: Docker containers provide a isolated environment for each experiment, preventing conflicts between different experiments.
Use Cases
Use cases for Docker in Academia:
Machine learning and data science: Docker can be used to create reproducible and scalable environments for training and evaluating machine learning models.
High-performance computing: Docker can be used to deploy applications on high-performance computing (HPC) clusters, making it easier to manage and scale applications.
Research software: Docker can be used to create and distribute research software, making it easier for other researchers to use and reproduce results.
Code examples:
Here is an example of how to create a Docker image for a machine learning experiment:
# Start by creating a Dockerfile
FROM python:3.8-slim-buster
# Install the required libraries
RUN pip install numpy scikit-learn pandas
# Copy the experiment code into the container
COPY experiment.py /app/experiment.py
# Set the working directory
WORKDIR /app
# Run the experiment when the container starts
CMD ["python", "experiment.py"]
# Build the Docker image
$ docker build -t experiment:1.0 .
# Run the experiment in a container
$ docker run --rm experiment:1.0
In this example, we start by defining a Docker image based on the python:3.8-slim-buster image. We then install the required libraries using the pip package manager. Next, we copy the experiment code into the container and set the working directory to /app. Finally, we specify that the experiment should be run when the container starts by using the CMD command.
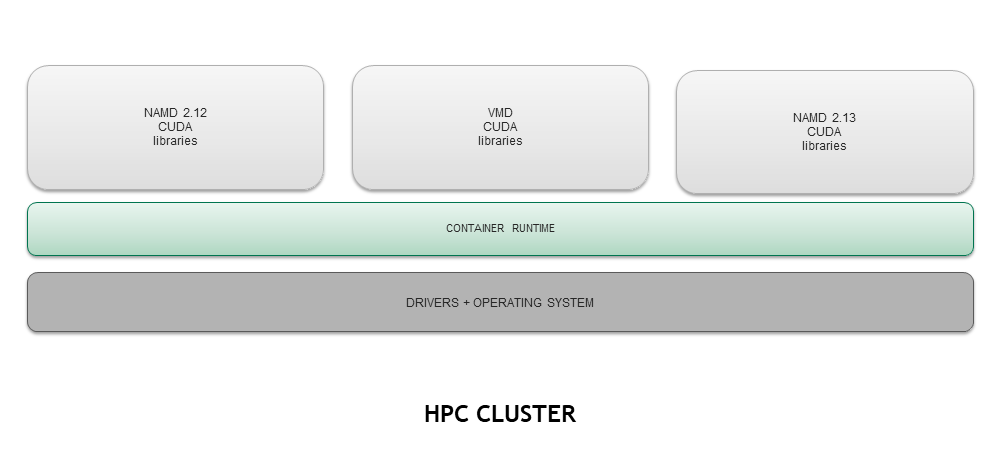
Here is an example of how to run an experiment on a high-performance computing cluster using Docker:
# Start by creating a Dockerfile
FROM ubuntu:20.04
# Install the required libraries
RUN apt-get update && apt-get install -y mpi-default-dev
# Copy the experiment code into the container
COPY experiment.c /app/experiment.c
# Set the working directory
WORKDIR /app
# Compile the experiment code
RUN mpicc experiment.c -o experiment
# Run the experiment when the container starts
CMD ["mpirun", "-np", "4", "./experiment"]
# Build the Docker image
$ docker build -t experiment:1.0 .
# Submit the job to the HPC cluster using Docker
$ sbatch --ntasks=4 --image=experiment:1.0 run_experiment.sh
# In the run_experiment.sh script:
#!/bin/bash
# Start the Docker container
docker run --rm experiment:1.0
In this example, we start by defining a Docker image based on the ubuntu:20.04 image and installing the required libraries, including MPI. We then copy the experiment code into the container and compile it using the mpicc compiler. The experiment is then run when the container starts using the mpirun command. To run the experiment on an HPC cluster, we submit a job using the sbatch command, specifying the number of tasks and the Docker image to use. The job is run using the run_experiment.sh script, which starts the Docker container.
Conclusion
In conclusion, Docker provides an easy-to-use platform for implementing containers in academia. It enables researchers and developers to collaborate more effectively, ensure reproducibility of results, and scale their experiments to large datasets. The code examples in this blog demonstrate how to create and run Docker containers for machine learning and high-performance computing experiments.